AB-UPT Showcase¶
The showcase provides a self-contained CLI for training, evaluating, and visualizing AB-UPT models on the DrivAerML automotive aerodynamics dataset. It demonstrates the preset-based interface with ready-to-use model configurations.
The full source code lives in recipes/aero_cfd/showcase/.
Important
All commands must be run from the recipes/aero_cfd/ directory with recipes/ on the Python path:
cd recipes/aero_cfd/
export PYTHONPATH=$(git -C ../.. rev-parse --show-toplevel)/recipes:$PYTHONPATH
Dataset¶
The showcase uses a 10x subsampled version of DrivAerML (~500 parametric car geometries with high-fidelity CFD results), hosted on HuggingFace: EmmiAI/DrivAerML_subsampled_10x.
Download with the noether-data CLI:
noether-data huggingface snapshot EmmiAI/DrivAerML_subsampled_10x /path/to/drivaerml
Or with huggingface-cli:
huggingface-cli download EmmiAI/DrivAerML_subsampled_10x \
--repo-type dataset \
--local-dir /path/to/drivaerml
Training¶
# Small model -- fast iteration / smoke tests
python -m showcase.cli train \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs
# Scaled model on GPU
python -m showcase.cli train \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--model-size scaled \
--accelerator gpu \
--precision float16
# With experiment tracking and force coefficient logging
python -m showcase.cli train \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--tracker wandb \
--tracker-project my-aero-project \
--compute-forces
Training automatically saves optimizer state for resumability. To continue a previous run:
python -m showcase.cli train \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--model-size scaled \
--accelerator gpu \
--resume-run-id 2026-04-09_abc12
Evaluation¶
# Anchor-resolution metrics + save predictions
python -m showcase.cli evaluate \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--run-id 2026-04-09_abc12
# With force coefficients (Cd/Cl) and VTK export
python -m showcase.cli evaluate \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--run-id 2026-04-09_abc12 \
--compute-forces \
--export-vtk
# Dense query inference for higher-resolution predictions
python -m showcase.cli evaluate \
--dataset-root /path/to/drivaerml \
--output-path /path/to/outputs \
--run-id 2026-04-09_abc12 \
--query-inference \
--num-inference-surface-points 20000
The --compute-forces flag computes drag and lift coefficient errors (Cd/Cl) per sample and logs them to the tracker.
It requires surface_area_vtp.pt and surface_normal_vtp.pt in each sample’s dataset directory.
The --export-vtk flag produces VTP point clouds for visualization in ParaView.
Model sizes¶
Size |
Hidden Dim |
Heads |
Decoder Blocks |
Geometry Points |
Supernodes |
Surface Anchors |
Volume Anchors |
|---|---|---|---|---|---|---|---|
|
192 |
3 |
2 |
16,384 |
1,024 |
512 |
512 |
|
384 |
6 |
6 |
125,000 |
32,000 |
16,000 |
32,000 |
|
384 |
6 |
6 |
16,384 |
4,096 |
2,048 |
4,096 |
small – Fast iteration and smoke tests. Default for CPU.
scaled – Full research configuration for GPU. Use
--precision float16for ~2x speedup.scaled_mps – Same architecture as
scaledwith reduced point budget for Apple Silicon MPS.
All model and pipeline parameters are defined in showcase/model_configs.py.
Results¶
Test set metrics on DrivAerML (10x subsampled), anchor-point resolution, 50 samples.
Training was run on a single H100 GPU with --precision float16.
Metric |
|
|
Improvement |
|---|---|---|---|
Surface Pressure L2 |
0.0800 |
0.0357 |
2.2x |
Surface Friction L2 |
0.1370 |
0.0680 |
2.0x |
Volume Velocity L2 |
0.0963 |
0.0518 |
1.9x |
Volume Pressure L2 |
0.1079 |
0.0538 |
2.0x |
Volume Vorticity L2 |
0.6577 |
0.2387 |
2.8x |
Mean |dCd| |
0.2818 |
0.2768 |
1.0x |
Mean |dCl| |
0.0645 |
0.0633 |
1.0x |
Train time |
~7h |
~28.5h |
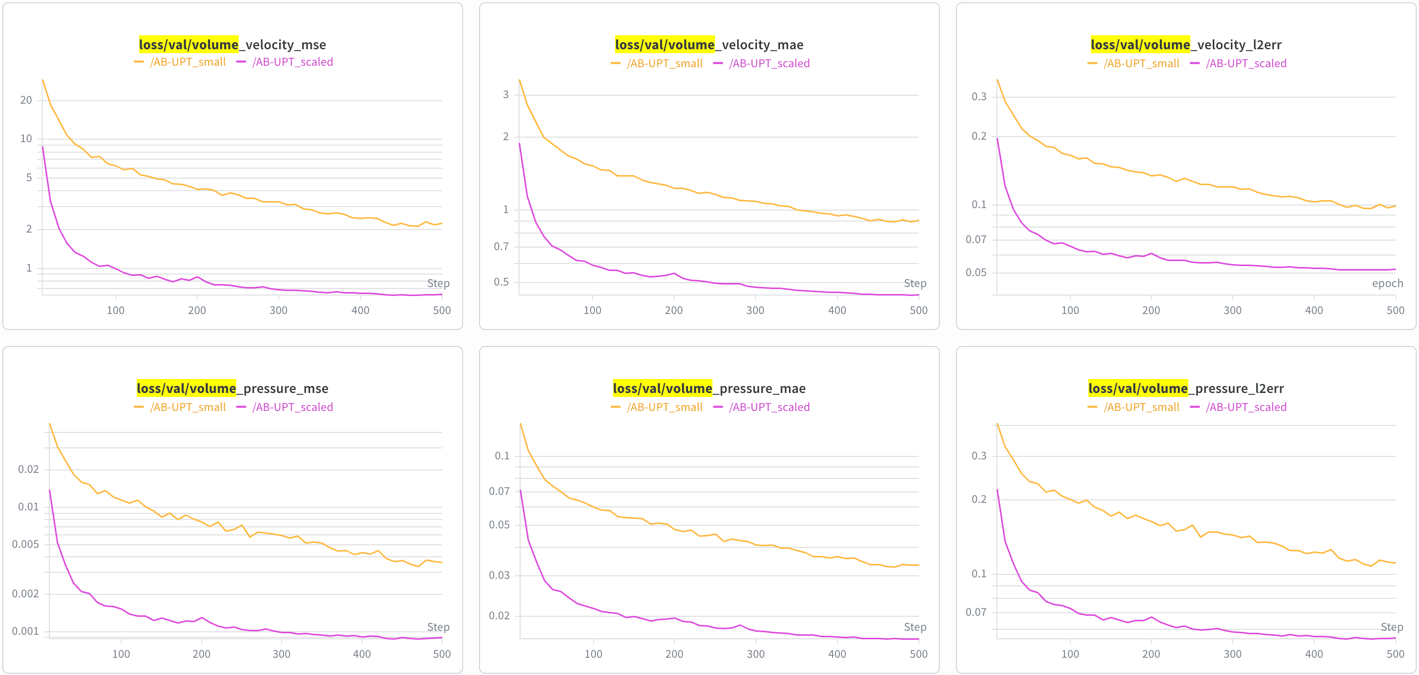
Training curves¶
Surface field losses (pressure, friction):
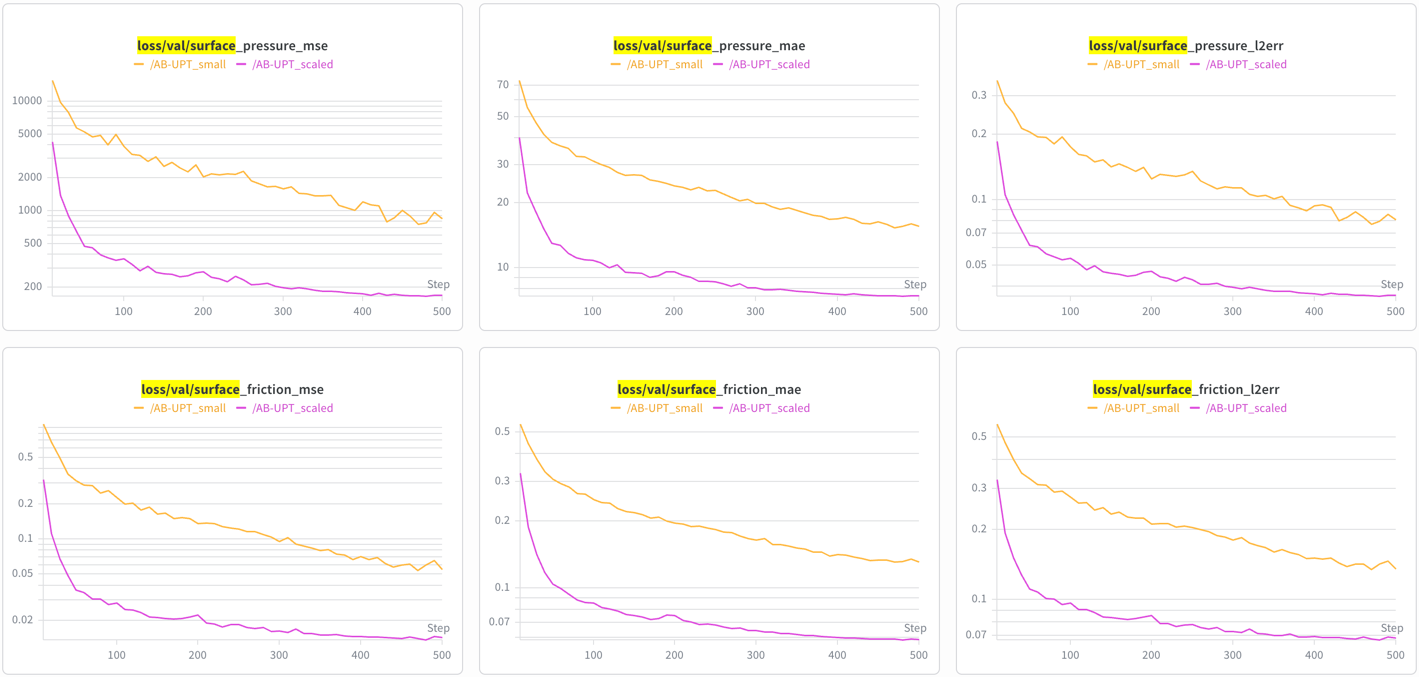
Volume field losses (velocity, pressure):
Customization¶
Adding a new model size:
Add an entry to MODEL_SIZES in model_configs.py and a corresponding value to the ModelSize enum.
Key relationships:
hidden_dimmust be divisible bynum_headsMore
num_domain_decoder_blocks= more expressive per-domain decoding (but slower)radiuscontrols the supernode pooling neighborhoodnum_geometry_supernodes<<num_geometry_points(compression ratio for the perceiver)
Changing training hyperparameters:
Loss field weights are in FIELD_WEIGHTS in model_configs.py. Optimizer and learning rate schedule are configured
in the preset (aero_cfd/presets/base.py). Defaults: Lion optimizer, lr=5e-5, weight_decay=0.05,
linear warmup + cosine decay.
Using a different dataset:
Create a new preset class inheriting from AeroCFDPreset, defining data_specs, normalizer_spec,
and pipeline parameters. See aero_cfd/presets/shapenet_car.py for a complete example with a different dataset.