Introduction to Noether Framework¶
Main Components¶
The Noether Framework is organized into the following submodules:
core- low-level components responsible for the heavy-lifting of the frameworkdata- data serving utilities (e.g., datasets, preprocessors, utils, etc.)io- data fetching and storage utilitiesinference- utilities for CLI/tooling to run inference pipelinemodeling- model building blocks and some of the SOTA architecturestraining- trainers, callbacks, and CLI/tooling to run the training pipeline
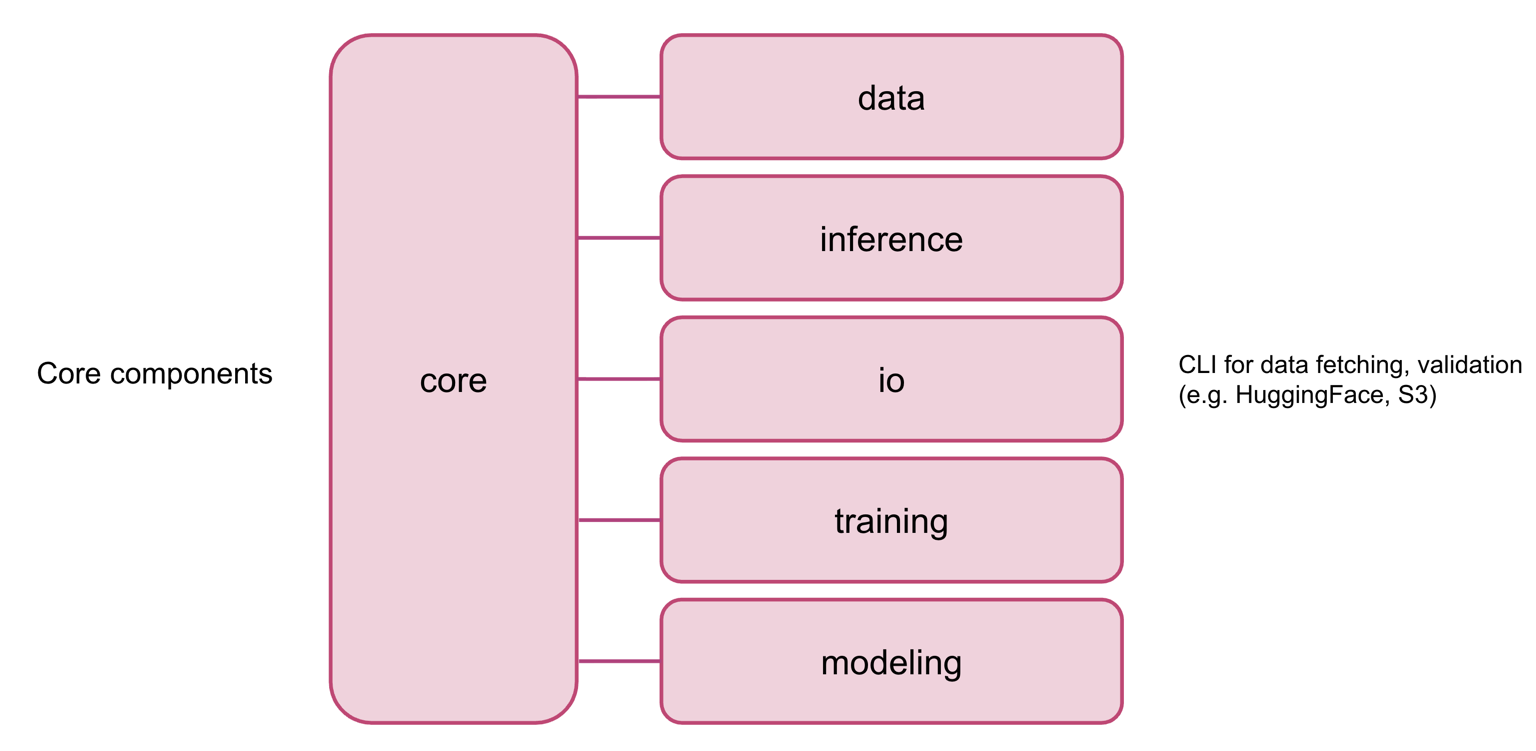
Core layering of the submodules¶
How Do They Interact¶
The interaction between existing modules is better described using a typical workflow. Let’s say, a user wants to train a model, like AB-UPT, to do so they have two options:
Use configuration files to set up an experiment
Use code and tailor it to specific needs
In either case, the same underlying shared codebase is used to ensure consistent behavior.
Our main buildings blocks are located in core. It takes care of things like object factories, callbacks, trackers,
schemas, etc. All of which have Base classes that can be used as abstract classes to create custom variations,
as well as ready-to-use implementations with clearly defined usage patterns. Those are usually located next to their
typical application, e.g. training callbacks will be in the training submodule, and so on.
To account for various levels of expertise (e.g. a seasoned ML engineer, a MSc/PhD student, a CFD expert, etc.)
we provide multiple abstraction levels. The higher-level modules, like data, modeling, etc., give a list of
convenient and frequently used blocks to get things going. They fully rely on core and are ready to be extended
with some custom logic when necessary. In most cases it is recommended to extend those modules first rather than diving
directly into the core itself.
For example, both inference and training rely on the modeling submodule as it provides the architectures
for model initialization. io on the other hand is pretty much standalone and mainly depends on the third-party
packages. Currently it supports data fetching and validation from HuggingFace and AWS S3. By sharing feedback
about your preferred way of storing and accessing data, you can help us prioritize future features.